

Natural Language Processing in the kitchen
Natural Language Processing is a field that covers computer understanding and manipulation of human language, and it’s ripe with possibilities for newsgathering. You usually hear about it in the context of analyzing large pools of legislation or other document sets, attempting to discover patterns or root out corruption. I decided to take it into the kitchen for my latest project: The Times California Cookbook recipe database.
The first phase of the project, the holiday edition, launched with more than 600 holiday-themed recipes from The Times Test Kitchen. It’s a large number, but there’s much more to come next year – we have close to another 5,000 recipes staged and nearly ready to go.
With only four months between the concept stage of the site and launch, the Data Desk had a tight time frame and limited resources to complete two parallel tasks: build the website and prepare the recipes for publication. The biggest challenge was preparing the recipes, which were stored in The Times library archive as, essentially, unstructured plain text. Parsing thousands of records by hand was unmanageable, so we needed a programmatic solution to get us most of the way there.
We had a pile of a couple thousand records – news stories, columns and more – and each record contained one or more recipes. We needed to do the following:
- Separate the recipes from the rest of the story, while keeping the story intact for display alongside the recipe later.
- Determine how many recipes there were – more than one in many cases, and counts up to a dozen weren’t particularly unusual.
- For each recipe, find the name, ingredients, steps, prep time, servings, nutrition and more.
- Load these into a database, preserving the relationships between the recipes that ran together in the newspaper.
Where to start?
The well-worn path here at the Data Desk would be to write a parser that looks for common patterns in formatting and punctuation. You can break up the text line by line, then look for one or more regular expression matches on each line. It might go something like this:
import re # Define our patterns for a step and ingredient # A step could have a number in front # followed by a period like "1." or an "*" step_pattern = re.compile(r'^(?:[0-9]{1,2}\.\s|\*)', re.S) # An ingredient could have a fraction in front like "1/2" or "1 1/4" ingredient_pattern = re.compile(r'^(?:[0-9]{1,3}\s|[0-9,/]{1,4}\s|[0-9]\s[0-9][/][0-9])', re.S) def tag(text): """ Attempt to classify a line of text as a "step" or "ingredient" based on the formatting or leading text. """ if step_pattern.match(text): return 'step' if ingredient_pattern.match(text): return 'ingredient' return None # Test it out tag('3 eggs') >>> 'ingredient' tag('1. Heat the oven to 375 degrees.') >>> 'step'
Then you can make an attempt to tag each line of the story with a recipe field – description, name, ingredient, step, nutrition, etc. – and write another script to assemble those parts into recipes that can be loaded into a database.
After looking at a few records it was immediately evident we wouldn’t be able to use pure regular expressions to parse them. We had decided to try to grab all of the recipes The Times had published from the year 2000 to present, and there were enormous differences in the formatting and structure over the years. We needed natural language processing and machine learning to parse it.
Enter NLTK
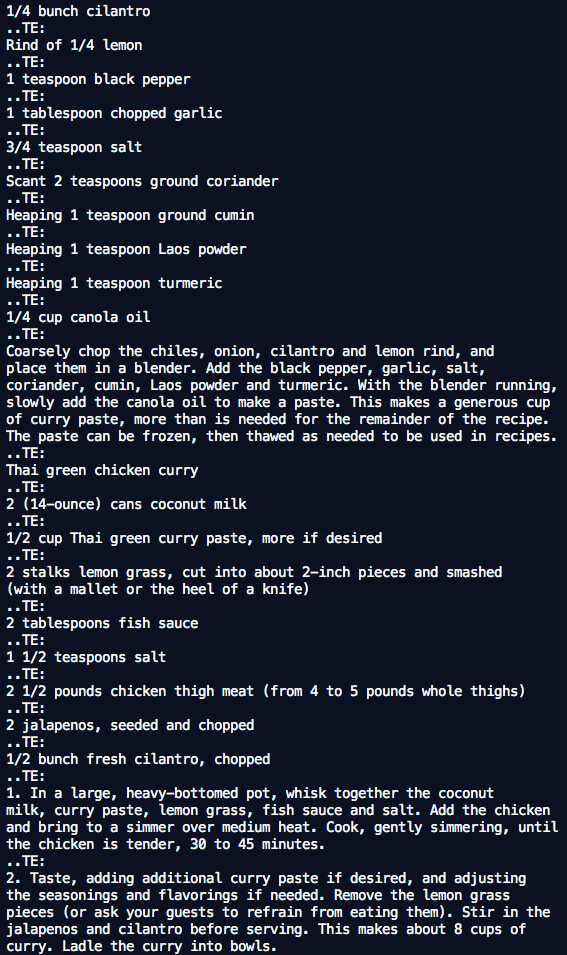
Natural language processing is a big field, and you can do a lot with it – the vast majority of which I will not cover here. Python, my programming language of choice, has an excellent library for natural language processing and machine learning called Natural Language Toolkit, or NLTK, which I primarily used for this process. At left is an example of what the raw recipes looked like coming out of our library archive.
One of the more common uses of NLTK is tagging text. You could, for example, have it tag a news story with topics or analyze an email to see if it’s spam. The very basic approach is to tokenize the text into words, then pass off those words into a classifier that you’ve trained with a set of already-tagged examples. The classifier then returns the best fitting tag for the text.
For recipes, we already have well-defined fields we need to extract. There will be ingredients, steps, nutrition, servings, prep time and possibly a couple more. We just need to train a classifier to tell the difference by passing it some examples we’ve done manually. After a bit of research and testing, I chose to go with a Maximum Entropy classifier because it seemed to fit the project best and was very accurate.
A basic approach might look something like this:
import nltk import pickle from nltk.classify import MaxentClassifier # Set up our training material in a nice dictionary. training = { 'ingredients': [ 'Pastry for 9-inch tart pan', 'Apple cider vinegar', '3 eggs', '1/4 cup sugar', ], 'steps': [ 'Sift the powdered sugar and cocoa powder together.', 'Coarsely crush the peppercorns using a mortar and pestle.', 'While the vegetables are cooking, scrub the pig ears clean and cut away any knobby bits of cartilage so they will lie flat.', 'Heat the oven to 375 degrees.', ] } # Set up a list that will contain all of our tagged examples, # which we will pass into the classifier at the end. training_set = [] for key, val in training.items(): for i in val: # Set up a list we can use for all of our features, # which are just individual words in this case. feats = [] # Before we can tokenize words, we need to break the # text out into sentences. sentences = nltk.sent_tokenize(i) for sentence in sentences: feats = feats + nltk.word_tokenize(sentence) # For this example, it's a good idea to normalize for case. # You may or may not need to do this. feats = [i.lower() for i in feats] # Each feature needs a value. A typical use for a case like this # is to use True or 1, though you can use almost any value for # a more complicated application or analysis. feats = dict([(i, True) for i in feats]) # NLTK expects you to feed a classifier a list of tuples # where each tuple is (features, tag). training_set.append((feats, key)) # Train up our classifier classifier = MaxentClassifier.train(training_set) # Test it out! # You need to feed the classifier your data in the same format you used # to train it, in this case individual lowercase words. classifier.classify({'apple': True, 'cider': True, 'vinegar': True}) >>> 'ingredients' # Save it to disk, if you want, because these can take a long time to train. outfile = open('my_pickle.pickle', 'wb') pickle.dump(classifier, outfile) outfile.close()
The built-in Maximum Entropy classifier can take an exceedingly long time to train, but NLTK can interface with several external machine-learning applications to make that process much quicker. I was able to install MegaM on my Mac, with some modifications, and used it with NLTK to great effect.
Deeper analysis
But that’s just a beginning, and what is typically described as a “bag of words” approach. To put it simply, the classifier learns how to tag your text based on the frequency of some of the words. It doesn’t account for the order of the words, or common phrases or anything else. Using this method I was able to tag fields with slightly more than 90% accuracy, which is pretty good. But we can do better.
If you think about how a recipe is written, there are more differences between the fields than the individual words like “butter” or “fry.” There might be common phrases like “heat the oven” or “at room temperature.”
There also might be differences in the grammar. For example, how can you correctly tag “Mini ricotta latkes with sour cherry sauce” as a recipe title and not an ingredient? Ingredients might have a reasonably predictable mix of adjectives, nouns and proper nouns while steps might have more verbs and determiners. A title would rarely have a pronoun but could include prepositions fairly often.
NLTK comes with a few methods to make this type of analysis much easier. It has a great part-of-speech tagger, for instance, as well as functions for pulling bi-grams and tri-grams (two and three word phrases) out of blocks of text. You can easily write a function that tokenizes text into sentences, then words, then tri-grams and parts of speech. Feed all of that into your classifier and you can tag text much more accurately.
It could look something like this:
import nltk from nltk.tag.simplify import simplify_wsj_tag def get_features(text): words = [] # Same steps to start as before sentences = nltk.sent_tokenize(text) for sentence in sentences: words = words + nltk.word_tokenize(sentence) # part of speech tag each of the words pos = nltk.pos_tag(words) # Sometimes it's helpful to simplify the tags NLTK returns by default. # I saw an increase in accuracy if I did this, but you may not # depending on the application. pos = [simplify_wsj_tag(tag) for word, tag in pos] # Then, convert the words to lowercase like before words = [i.lower() for i in words] # Grab the trigrams trigrams = nltk.trigrams(words) # We need to concatinate the trigrams into a single string to process trigrams = ["%s/%s/%s" % (i[0], i[1], i[2]) for i in trigrams] # Get our final dict rolling features = words + pos + trigrams # get our feature dict rolling features = dict([(i, True) for i in features]) return features # Try it out text = "Transfer the pan to a wire rack to cool for 15 minutes." get_features(text) >>> {'DET': True, 'transfer/the/pan': True, 'for/15/minutes': True, 'rack/to/cool': True, 'wire': True, 'wire/rack/to': True, 'for': True, 'to': True, 'transfer': True, 'to/a/wire': True, '.': True, 'TO': True, 'NUM': True, 'NP': True, 'pan': True, 'a/wire/rack': True, 'the/pan/to': True, 'N': True, 'P': True, 'pan/to/a': True, '15/minutes/.': True, 'cool': True, 'a': True, '15': True, 'to/cool/for': True, 'cool/for/15': True, 'the': True, 'minutes': True, 'rack': True}
Wrapping it up
Using a combination of these methods I was able to pull recipes out of news stories very successfully. To get the classifier working really well you need to train it on a large, random sample of your data.
I parsed about 10 or 20 records by hand to get started, then created a small Django app to randomly load a record and attempt to parse it. I corrected the tags that were wrong, saved the correct version to a database, and periodically retrained the classifier using the new samples. I ended up with a couple hundred parsed records, and the classifier (which has some built-in methods for testing) was about 98% accurate.
I wrote a parsing script that incorporated some regular expressions and a bit of if/else logic to try to tag as much as I could from formatting, then used NLTK to tag the rest. After the tagging, the story still had to be assembled into one or more discrete recipes and loaded into a database so that humans could review them.
That process was relatively straightforward, but I did have to build a custom admin for a small group of people to compare the original record and parsed output side by side. In the end every record had to be reviewed by hand, and many of them needed one or more small tweaks. Only about one in 20 had structural problems. A big thanks to Maloy Moore, Tenny Tatusian and the Food section staff for combing through all of the records by hand. Computers can really only do so much.
If you want to learn more I highly recommend the book Natural Language Processing with Python, which I read before embarking on this project.

